LLM API 분석 (트랜잭션 연계)
LLM Observability는 WhaTap APM과 통합되어 LLM API 호출을 애플리케이션 트랜잭션의 일부로 추적합니다. 트랜잭션 프로파일에서 LLM HTTPC 스텝을 클릭하면 LLM API 상세 Drawer가 열리며, 프롬프트 입력/출력, 토큰 사용량, 비용, 에러 정보는 물론 GPU 인프라 상관관계까지 LLM API 분석에서 확인할 수 있습니다.
프롬프트 입력/출력 조회에는 로그 읽기 권한이 필요합니다.
진입 방법
- LLM 대시보드의 히트맵 또는 트랜잭션 검색 등에서 트랜잭션을 선택합니다.
- 트랜잭션 프로파일 화면에서 LLM HTTPC 스텝(LLM 프로바이더 URL로 호출된 HTTP 외부 호출)을 클릭합니다.
- 우측에서 LLM API 상세 Drawer가 열립니다.
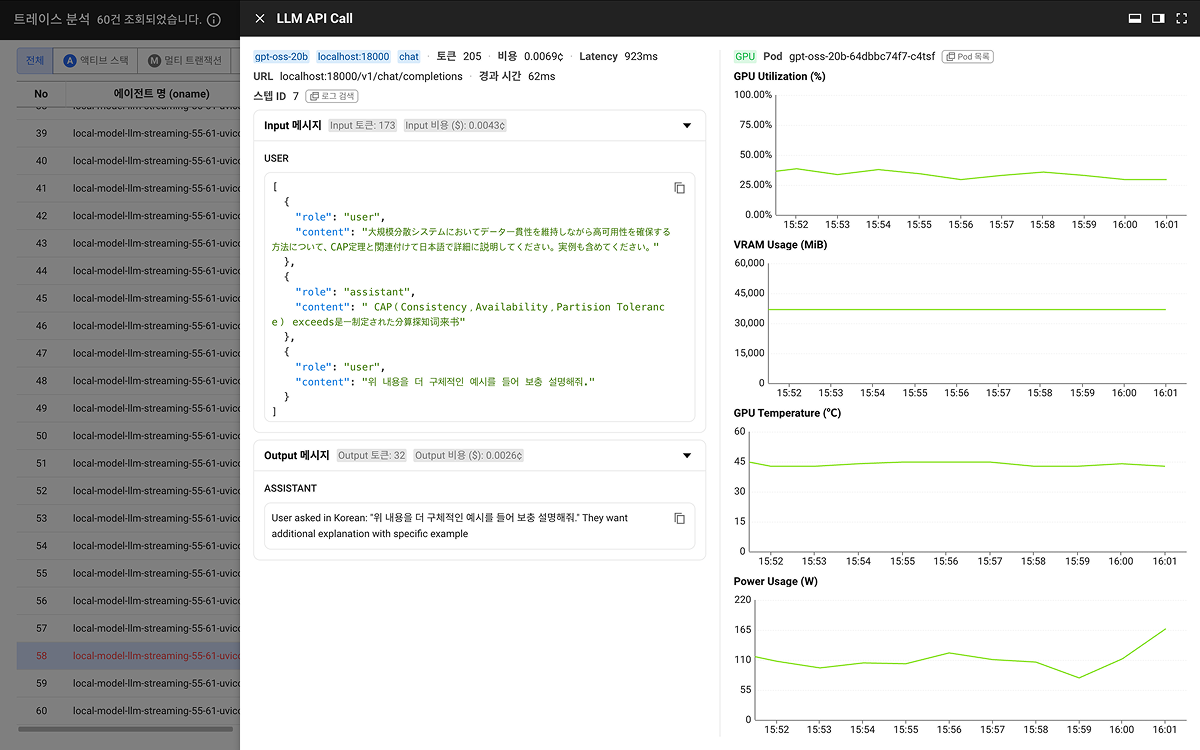
요약 및 프롬프트
LLM 호출의 핵심 정보를 한눈에 보여주고, 프롬프트 입력/출력 원본을 확인할 수 있는 영역입니다.
Identity 태그
호출 대상 모델과 프로바이더 정보를 태그 형태로 표시합니다.
| Tag | Description | Example |
|---|---|---|
Model | 사용된 LLM 모델명 | gpt-4o, claude-sonnet-4-20250514 |
Provider | LLM API 프로바이더 | api.openai.com, api.anthropic.com |
Operation | 호출의 Operation Type | chat, completion |
호출이 실패한 경우(success=false) 빨간색 Error 태그가 추가로 표시됩니다.
핵심 수치 지표
Identity 태그 옆에 인라인으로 표시됩니다.
| Metric | Description |
|---|---|
Token | 전체 토큰 수 (Input + Output) |
Cost | 해당 호출의 비용 ($) |
Latency | 요청 시작~응답 완료 시간 (ms) |
HTTP 정보
| Property | Description |
|---|---|
URL | 호출 엔드포인트 (host:port + path) |
Elapsed | HTTP 호출 소요 시간 (ms) |
Step ID | 이 LLM 호출의 고유 식별자. 로그 탐색으로 이동하는 기준 키입니다. |
Step ID 옆의 로그 탐색 버튼을 클릭하면, 해당 Step ID로 필터링된 로그 탐색기가 새 창에서 열립니다.
에러 정보
호출에 에러가 발생한 경우에만 표시됩니다.
| Property | Description |
|---|---|
Error Class | 에러 클래스명 (예: RateLimitError, TimeoutError) |
Error Message | 에러 상세 메시지 |
프롬프트 입력 (Input)
접기/펼치기가 가능한 섹션으로, LLM에 전달된 입력 메시지를 표시합니다.
헤더 뱃지
| Badge | Description |
|---|---|
Input Tokens | 입력 토큰 수 |
Cached Tokens | 캐시에서 가져온 토큰 수 (해당 시에만 표시) |
Input Cost ($) | 입력 비용 |
메시지 유형
| Label | Description |
|---|---|
| SYSTEM | 시스템 메시지. 모델의 역할과 동작을 정의하는 지시문입니다. |
| USER | 사용자 입력 메시지. 실제 프롬프트 내용입니다. |
메시지가 청크(chunk)로 분할되어 수집된 경우, 자동으로 올바른 순서로 조립하여 완전한 텍스트로 표시합니다.
모델 응답 (Output)
접기/펼치기가 가능한 섹션으로, 모델이 생성한 응답을 표시합니다.
헤더 뱃지
| Badge | Description |
|---|---|
Output Tokens | 출력 토큰 수 |
Reasoning Tokens | 추론(Reasoning) 토큰 수 (해당 시에만 표시) |
Output Cost ($) | 출력 비용 |
메시지 유형
| Label | Description |
|---|---|
| ASSISTANT | 모델의 텍스트 응답입니다. |
| TOOL CALL | 모델이 요청한 도구 호출(Function Calling) 내용입니다. |
| TOOL RESULT | 도구 호출의 실행 결과입니다. |
GPU 상관관계
멀티 트랜잭션(mtid가 존재하는 경우)일 때 Drawer 우측에 표시됩니다. LLM 호출을 처리한 Pod의 GPU 인프라 상태를 실시간 차트로 보여주어, 모델 응답 지연이 GPU 리소스 부족 때문인지 판단할 수 있습니다.
GPU 정보 헤더
| Property | Description |
|---|---|
Pod | LLM 추론을 수행한 Kubernetes Pod 이름 |
| Pod 상세 버튼 | 클릭 시 Kubernetes 모니터링의 Pod 상세 페이지가 새 창에서 열립니다. |
GPU 차트
LLM 호출 시점 전후 5분 범위의 GPU 메트릭을 라인 차트로 표시합니다.
| Chart | Metric | Unit | Description |
|---|---|---|---|
| GPU Utilization | DCGM_FI_DEV_WEIGHTED_GPU_UTIL | % | GPU 연산 자원의 사용률. 100%에 가까우면 GPU가 포화 상태이며, LLM 응답 지연의 원인일 수 있습니다. |
| VRAM Usage | DCGM_FI_DEV_FB_USED | MiB | GPU 메모리(Video RAM) 사용량. 모델 로딩과 추론에 사용되며, 부족하면 OOM이나 스왑이 발생합니다. |
| GPU Temperature | DCGM_FI_DEV_GPU_TEMP | °C | GPU 온도. 과열 시 자동 스로틀링이 발생하여 성능이 저하됩니다. |
| Power Usage | DCGM_FI_DEV_POWER_USAGE | W | GPU 전력 소비. Utilization과 함께 보면 실제 연산 부하를 파악할 수 있습니다. |
GPU 상관관계는 다음 조건이 모두 충족될 때 표시됩니다.
- 트랜잭션이 멀티 트랜잭션(mtid 존재)인 경우
- LLM 추론을 수행한 Pod 이름이 식별된 경우
- 연계된 Kubernetes 프로젝트에서 DCGM GPU 메트릭이 수집되고 있는 경우
분석 시나리오
LLM 응답 지연 원인 파악
- LLM 대시보드의 히트맵에서 응답 시간이 긴 트랜잭션을 클릭합니다.
- 트랜잭션 프로파일에서 LLM HTTPC 스텝의 Elapsed 시간을 확인합니다.
- LLM API �상세 Drawer를 열어 Latency 값과 GPU Utilization 차트를 비교합니다.
- GPU Utilization이 높은 상태에서 Latency가 급증했다면 GPU 리소스 부족이 원인입니다.
- GPU Utilization이 낮은데 Latency가 높다면 프로바이더 측 지연(큐 대기, Rate Limit 등)을 의심합니다.
에러 발생 LLM 호출 재현
- 트랜잭션 프로파일에서 에러가 표시된 LLM HTTPC 스텝을 클릭합니다.
- Drawer의 Error Class와 Error Message로 에러 유형을 확인합니다.
- 프롬프트 입력(Input) 섹션에서 SYSTEM 메시지와 USER 메시지 원본을 확인합니다.
- 수집된 프롬프트 원본과 모델/파라미터 정보로 동일 호출을 재현하여 문제를 분석합니다.
비용이 높은 LLM 호출 분석
- 비용 분석 페이지에서 비용이 높은 시간대를 식별합니다.
- 해당 시간대의 트랜잭션을 검색하여 프로파일을 열고, LLM HTTPC 스텝을 클릭합니다.
- Drawer에서 Token 수와 Cost를 확인합니다.
- 프롬프트 입력 섹션에서 Input Tokens 뱃지를 확인하고, 프롬프트가 불필요하게 긴지 점검합니다.
- Cached Tokens 뱃지가 0이면 캐싱이 적용되지 않은 호출이므로, 캐싱 대상 프롬프트인지 검토합니다.
참고
데이터 수집 구조
LLM API 상세 Drawer는 두 가지 데이터 소스를 결합합니다.
| Data Source | Description | Usage |
|---|---|---|
| APM 트레이스 | HTTP 호출 정보 (URL, host, port, elapsed, 에러 클래스/메시지), Step ID | 트랜잭션 프로파일에서의 호출 식별 및 HTTP 수준 정보 표시 |
#LlmCallLog 로그 | 모델, 프로바이더, 토큰, 비용, 성공 여부, 메시지 내용 | 프롬프트 원본 복원 및 LLM 수준 메타데이터 표시 |
두 데이터는 Step ID를 기준으로 연결됩니다.
메시지 청크 조립
LLM 프롬프트와 응답은 길이가 길 수 있으므로 서버에서 여러 청크(chunk)로 분할하여 수집됩니다. Drawer는 chunk_index 필드를 기준으로 청크를 올바른 순서로 조립하여 완전한 메시지를 복원합니다. 타��입당 최대 100개 청크까지 지원합니다.